
About UTF-8
UTF-8 소개
유니코드. 전 세계의 문자를 통일된 규칙으로 표현한 체계. 1990년 IBM, Microsoft, Apple등의 회사가 전세계의 모든 문자에 0x0000 ~ 0xFFFF까지(65,536) 숫자를 매겨놓은 규칙. 제정할 때 고려하지 못한 문자를 표현하기 위해 15개의 세트(플레인이라고 함)가 추가되었다. 그래서, U+0000 처럼 4개의 nibble로 표현된 유니코드를 기본 플레인(BMP, Basic multilingual plain)이라고 표시하고 추가된 15개의 플레인은 U+10000 ~ U+F0000 처럼 5개의 nibble로 표현한다.
UCS-2는 추가된 15개의 플레인을 무시하고 BMP만을 사용하는 인코딩 방식. UTF-16은 BMP 문자는 UCS-2로 그 이상의 문자는 32비트로 인코딩 방식. UTF-32는 16개의 플레인으로 표현되는 모든 문자를 4바이트의 문자로 표현하는 방식.
UTF-8은 1~4 바이트의 가변길이 유니코드 인코딩이다. 가장 많이 사용되는 코드는 1 바이트 (ASCII), 사용 빈도가 적은 언어에는 더 많은 바이트를 할당한다. 한글의 경우 문자 당 3 바이트 할당.
아래 그림 1에서 확인할 수 있는 것처럼 UTF-8이 가장 널리 사용된다.
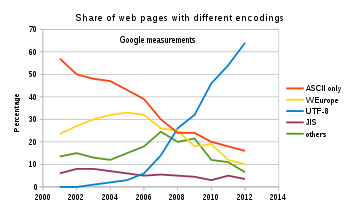 그림 1. utf-8 사용 추세
그림 1. utf-8 사용 추세
포렌식에서 UTF-8
포렌식 분석 시 도구가 증거 데이터를 정확하게 분석하지 못할 경우, 분석관이 직접 헥스 에디터를 보면서 분석해야 하는 경우가 있다. 획득한 이미지를 헥스 뷰어로 볼 때 연속된 헥사 값에서 한글을 찾아내는 것은 매우 중요하다. 아래 표 1에서 보는 것처럼 3바이트로 표현되는 한글은 각 바이트에 1110, 10, 10 라는 숫자가 할당된다. 즉, 이진수 1110은 16진수로 0xE 이므로 헥스 뷰어에서 0xE로 시작되는 3바이트를 한글이라고 가정하고 해석하면 한글을 쉽게 찾을 수 있다.
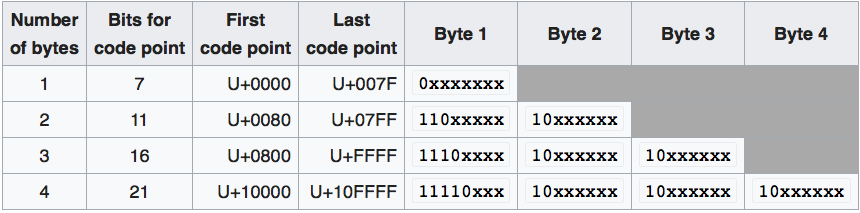 표 1. utf-8 변환표
표 1. utf-8 변환표
연습
“이창하” 를 편집기를 이용해서 utf-8로 저장하고 Hex Viewer로 읽으면 => [EC 9D B4 EC B0 BD ED 95 98]
EC 9D B4 => 1110(1100) . 10(011101) . 10(110100)
=> 1100 . 011101 . 110100
=> 11000111 . 01110100
=> 1100 . 0111 . 0111 . 0100
=> C774 ([U+C774](https://codepoints.net/U+C774))
EC B0 BD => U+CC3D
ED 95 98 => U+D558아래 소스코드는 utf-8로 저장된 한글 데이터를 읽어서 해당 unicode로 출력하는 예제이다. 변수 path에 실제 파일의 경로를 주면 된다.
Ruby: utf8_to_unicode_point.rb
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#!/usr/bin/env ruby
class String
def to_codepoint
self.bytes.each_slice(3).map { |s|
first = (s[0] & 0xf0) >> 4
return nil unless first == 0b1110
init = s.shift & 0xff
s.reduce(init) { |r, e| r << 6 | e & 0x3f }
}
end
end
chars = File.open(path, "r:UTF-8") { |f| f.read.chomp }
chars.to_codepoint.each { |cp|
p "U+#{cp.to_s(16).upcase}"
}
Leave a comment